MAP#
Struktur der Modulabschlussprüfung
Ihr sucht euch einen Datensatz inkl. Fragestellung, die im pädagogischen Bereich zu verorten ist (z.B., Unterscheidet sich die Lesefähigkeit von Schüler und Schülerinnen in Abhängigkeit der Anzahl von Büchern daheim, o.ä)
Wenn ihr dies gemacht habt, schreibt ihr mir eine E-Mail. Wir treffen uns dann entweder in meinem Büro am Campus oder via Zoom. Dort besprechen wir Datensatz und Fragestellung und ich gebe euch eine Hilfestellung, wie ihr das ganze angehen könntet.
Gliederung#
Für die MAP ist es empfehlenswert, dass ihr euch an der folgenden Gliederung entlang hangelt. Ihr könnt davon aber auch abweichen, solange alle wichtigen und relevanten Informationen in logischer Reihenfolge vorkommen.
Einführung: Hier sollte klar werden, welche theoretischen Hintergründe eure Fragestellung hat; Warum erwartet ihr, dass die Anzahl an Büchern daheim (X) einen Einfluss auf die Lesefähigkeit (y) hat? Warum ist es wichtig diese Konstrukte (X und y) zu untersuchen? Eine Fragestellung sollte klar, präzise und beantwortbar sein! Definiert die spezifischen Begriffe, die Teil eurer Fragestellung sind, insofern es sich um keine alltäglichen Begriffe handelt. Es sollte eindeutig sein, was gemeint ist. Versucht eure Fragestellung durch ein theoretisches Modell oder eine Erklärung zu motivieren. Das könnten zum Beispiel Theorien aus der Entwicklungspsychologie, Didaktik oder Lernpsychologie sein. Was für Ergebnisse erwartet ihr? Zum Ende des des Einführungsteils solltet ihr dann eine Fragestellung definiert haben. Ihr leitet also zunächst her, welche Konstrukte ihr untersuchen wollt, weshalb diese relevant sind und formuliert schlussendlich die Fragestellung.
Beispiel: Hat die Hintergrundmusik während des Lesens einen Einfluss auf die Konzentration von Schülerinnen? -> Mit Konzentration meinen wir, wie viele Fragen zum Text richtig beantwortet wurden -> Laut der kognitiven Belastungstheorie kann zu viel Ablenkung die Verarbeitung von Informationen stören -> Wir möchten wissen, ob sich das Lesen im Klassenzimmer durch Musik verändert – also: Beeinflusst Musik die Leseleistung?
Methodenteil: Hier solltet ihr beschreiben, mit welchen Mitteln ihr eure Fragestellung beantwortet. Welchen Datensatz habt ihr und woher? Was für Informationen stecken im Datensatz, wie lässt er sich charakterisieren (Mittelwerte, Standardabweichungen, Korrelationen zwischen Variablen) ? Wie groß ist die Stichprobe im Datensatz? Welche Variablen aus dem Datensatz benötigt ihr für die Beantwortung eurer Fragestellung? Mit Hilfe welcher Software wertet ihr die Fragestellung aus? Welche Module benutzt ihr hier für? Welches Machine Learning Model verwendet ihr? Was ist der Output des Models? ; Im Methodenteil ist also viel Platz, um eurer ganzes Vorhaben auf methodischer Art und Weise zu beschreiben. Hier bietet es sich auch an, eure Daten zu visualisieren (denkt unbedingt an Achsenbeschriftungen!)
Beispiel: Unser Datensatz enthält Antworten von 50 Schülerinnen auf einen Lesetest -> Die Schülerinnen waren zwischen 8 und 10 Jahre (durchschnitt = .. )alt. Jeder hat denselben Text gelesen -> Wir haben mit Python gearbeitet und das Modul pandas benutzt, um die Daten auszuwerten -> Das Modell soll lernen, ob jemand den Text gut verstanden hat – nur auf Basis der Anzahl richtig beantworteter Fragen -> Wir zeigen mit einem Balkendiagramm, wie viele Schülerinnen mit und ohne Musik gut abgeschnitten haben
Ergebnisteil: Hier solltet ihr eure Ergebnisse aufzählen und beschreiben. Was für Ergebnisse hat euer Model produziert? Visualisiert die Ergebnisse!
Beispiel: Ein Genauigkeitswert von 0.85 bedeutet: Das Modell lag in 85 von 100 Fällen richtig -> Die Schülerinnen, die ohne Musik gelesen haben, konnten sich besser konzentrieren -> Mit Musik waren im Schnitt 3 Aufgaben mehr falsch als ohne Musik.
Diskussion: Hier solltet ihr beschreiben, wie sich die Ergebnisse in den theoretischen Rahmen einordnen und wie die Ergebnisse zur Fragestellung stehen. In der Diskussion solltet ihr euer Vorhaben reflektieren: Was sind mögliche Gründe für (nicht) erwartete Ergebnisse? Was für folge Analysen würden sich anbieten? Was könnten eure Ergebnisse für die Praxis bedeuten? Was könnte man noch besser machen? Was könnte man noch erforschen?
Beispiel: Die Ergebnisse ordnen sich in die Theorie zur kognitiven Belastungstheorie ein, dennoch ist die Stichprobe sehr selektiv (zum Beispiel wenn euer Datensatz nur die Daten von Kindern aus westlichen Schulen hat) und es steht offen, ob der Effekt in einer anderen Stichprobe übertragbar wäre…
Ihr solltet dann jeweils die relevanten Code Zeilen als Bild mitaufnehmen (z.b. als Screenshot)
Beispiel: Der hier verwendete Datensatz entstammt aus der Studie von Author et al. Der Datensatz wird mit dem Pandas Modul eingelesen.
import pandas as pd
df = pd.read_csv("Datensatz.csv")
Wir überprüfen wie hoch die Korrelationen zwischen den Variablen sind…
df.corr()
Es ist euch frei, ob ihr Tabellenoutputs aus google colab kopiert und zeigt, oder ob ihr eure eigenen Tabellen erstellt. Beides ist in Ordnung.
Formatierung#
Text auf deutsch oder englisch
Schriftart im Text: Arial (11) oder Times New Roman (12)
Schriftart Kapitelüberschriften: Arial (14) oder Times New Roman (15)
Zeilenabstand 1.5
Textausrichtung: Linksbündig
Fortlaufende Kapitelnummerierungen
Zitationsstil: Einer, mit dem ihr vertraut seid. Hier gibt es keine konkreten Vorgaben.
Eurer finales Dokument sollte nicht über 20 Seiten (inkl code snippets und Abbildungen, Tabellen etc) haben. Es gibt keine Mindestanzahl, aber realistischerweise solltet ihr zwischen 10 und 15 Seiten (Bedeutet, inkl. Text, Abbildungen und Code Snippets) landen. Das Literaturverzeichnis zählt NICHT in die maximale Seitenanzahl mit rein, das Titelblatt und das Inhaltsverzeichnis ebenso wenig.
Notebooks und co.#
Für die MAP werde ich euch kein eigenes Notebook schicken. Ihr könnt einfach über euren Google Account eine eigene google colab session starten. Hierfür klickt ihr auf diesen Link. Ihr solltet dann so was in der Art sehen
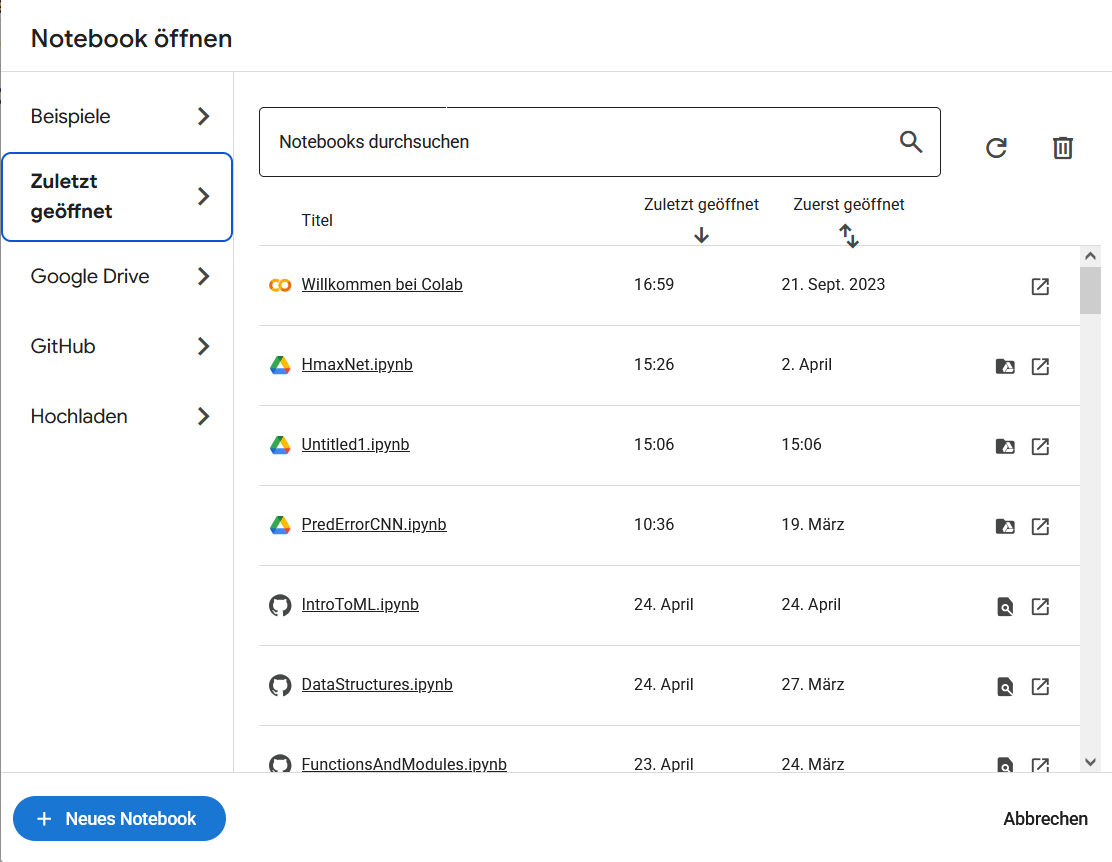
Klickt einfach auf
Neues Notebookund schon habt ihr eure eigene Python Session gestartet. In aller Regel wird dieses Notebook dann automatisch in euremgoogle drivegespeichert. Denkt dennoch dran, es lieber einmal mehr als einmal zu wenig local herunterzuladen.Am besten wäre es, wenn ihr den Text in Word schreibt und dann Visualisierungen etc. und eure Codezellen als Bild einfügt. Wenn ihr die MAP abgebt schickt ihr mir bitte dann das Notebook und das Dokument als PDF Datei! Bewertungsgrundlage der MAP wird der von euch geschrieben Text, die gewählten Analysen und die Interpretation und Diskussion der Ergebnisse sein. Die Qualität eures Codes bzw der Code als solcher wird nicht bewertet.
Weiteres#
Solltet ihr noch Fragen haben, schreibt mir eine E-Mail! Ich werde das Dokument fortlaufend aktualisieren.
Ich wünsche euch viel Spaß und Erfolg beim Bearbeiten der MAP ! :)
MINI-Beispiel-MAP: Einfluss von Bildschirmzeit auf Schulleistung#
Einführung#
Digitale Medien sind fester Bestandteil des Alltags von Kindern und Jugendlichen. Einige Studien (Quelle) zeigen einen negativen Zusammenhang zwischen Bildschirmzeit und schulischer Leistung, andere wiederum (Quelle) betonen den Einfluss von Art und Inhalt der Nutzung.
Fragestellung: Hat die tägliche Bildschirmzeit einen Einfluss auf die Noten von Schüler*innen?
Methodenteil#
Wir nutzen einen zufällig erzeugten Datensatz mit folgenden Variablen:
screen_time(in Stunden pro Tag)grade(Durchschnittsnote auf einer Skala von 1 bis 6)gender(weiblich/männlich/divers)
Die Daten werden in Python (pandas, seaborn) verarbeitet und visualisiert.
In diesem Datensatz sind N Schüler vertreten (x% weiblich, x% männlich, x% divers); Durchschnittsnote ist xyz, durchschnittliche screen time ist ….
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# Zufallsdaten erzeugen
np.random.seed(42)
n = 100
df = pd.DataFrame({
"screen_time": np.round(np.random.normal(4, 1.5, n), 1).clip(0, 10),
"grade": np.round(np.random.normal(3, 0.8, n), 1).clip(1, 6),
"gender": np.random.choice(["weiblich", "männlich", "divers"], n)
})
Ergebnisse#
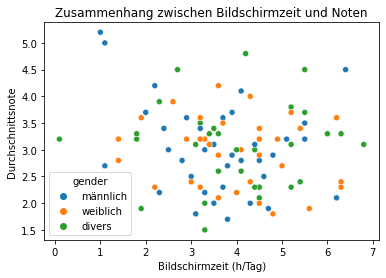
Wir betrachten zunächst den Zusammenhang zwischen Bildschirmzeit und Noten
sns.scatterplot(data=df, x="screen_time", y="grade", hue="gender")
plt.title("Zusammenhang zwischen Bildschirmzeit und Noten")
plt.xlabel("Bildschirmzeit (h/Tag)")
plt.ylabel("Durchschnittsnote")
plt.show()
Diskussion#
In der Visualisierung zeigt sich ein leichter positiver Zusammenhang zwischen Bildschirmzeit und schlechteren Noten. Dies entspricht bestehenden Annahmen, sollte aber differenziert betrachtet werden, zum Beispiel mit einem Machine Learning Model.
Keine Aussagen über Kausalität sind möglich
Zusätzlich informative Variablen wie Lernzeit oder Medientyp fehlen (siehe Theorie xyz von Author abc (1890))
Keine repräsentative Stichprobe
Ausblick: Weitere Analysen könnten Unterschiede zwischen Geschlechtern oder Altersgruppen betrachten oder die Bildschirmzeit nach Aktivitätstypen differenzieren (z. B. Lernen vs. Social Media).